
こんにちは、佐藤です。第3回はオンプレミスでは必要なかった運用のポイントをご紹介します。
そもそもシステムの運用とは?
まずシステムの運用で代表的なのは、障害監視、性能監視、バックアップなどシステムの安定稼働を目的としたもの、ファイアウォールの設定変更やバージョンアップ等、何らかの要求に伴う変更作業があります。もちろん、これら以外にもシステムや組織によって様々な対応が運用として定義されている場合があると思いますが、ここでは代表的なものをピックアップしてクラウド移行後に最低限おさえておきたいシステム運用についてご紹介していきます。
クラウドでの運用のポイント
クラウドに移行したシステムは物理的な保守・運用から開放され、運用担当者はシステムの性能維持や改善に集中することができます。一方、ブラックボックス化されている部分で障害が発生した場合、どのように検知すればよいのか?何も手立てはないのか?など事前に起こりうるリスクを整理して運用の中に組み込んでおく必要があります。この考え方事態はオンプレミスと変わりはありませんが、クラウドの場合考慮するポイントが変わります。
(クラウドに移行したシステムでの考慮ポイントの例)
・利用者が管理できないクラウド内のネットワークで障害が発生した場合どのように検知、対応するか?
・これまで監視エージェントをインストールして取得していたログ、性能情報はエージェントがインストールできないPaaSではどのように取得、監視すればよいか?
・クラウドが提供するサービスとしてのバックアップ機能でバックアップが失敗した場合どのように検知するか?
・クラウドは従量課金のため、当初見積もった費用と実際にかかる費用でギャップが発生していないか?
・ポータルから簡単にインフラ構成を作成・変更できるのは良いが変更管理、構成管理はどのようにすればよいのか?
それでは順番に説明していきます。
Design for Failureを前提とした運用
Azureに限らず、クラウドは何かしらの障害が常に発生する可能性があることを前提に設計、構築、運用をすることが重要です。クラウド事業者がサービス毎にSLAを提供している場合もありますが、99.9%の可用性だとしても月間で約40分の停止時間を許容するという程度です。また、この停止時間をオーバーしても返金があるだけでビジネス的機会損失の費用を保証してくれるものではありません。
オンプレミスと比較して品質が悪いということを言っているわけではありませんが、ネットワーク、ストレージ、サーバなどクラウドの基本的なインフラ部分で障害が発生する可能性があることは十分に理解して運用する必要があります。
実際、小さな障害は日々発生しており、私も何度もネットワーク障害、ストレージ障害、サーバ障害によるシステム障害対応を経験しています。また、年に数回の頻度で大規模障害も発生しています。Azureでも2021年2月にストレージ障害、9月にAzure Active Directoryの大規模障害が発生しネットニュースを騒がせました。AWSも9月に大規模なネットワーク障害が発生し、ネットニュースだけでなくテレビでも大体的に放映されましたので記憶にも新しいかと思います。
重要なのは、そのような障害が発生することを前提とし、システムとしてのサービスレベルを設計段階で設定、そのサービスレベルを維持するための運用設計、運用を行うことがとても重要ということです。たとえばSLA 99.99%を目標としているシステムの場合、障害発生時、人が介在して判断を行って復旧作業をしていては許容されているサービス停止時間をオーバーしてしまいますので、一次対応作業は自動化しておくことが必須となります。
一方、SLAが高くないシステムに対しては過度に高度な運用を適用する必要はありません。費用対効果のバランスと事前にステークホルダーと認識をあわせておくということがとても重要です。その判断の指標となるのがシステムとしてのサービスレベルになりますので、設計段階でしっかりと定義しておきましょう。
障害監視
障害が発生した際に迅速に検知することが重要になります。VM(仮想マシン)にエージェント入れて監視できる部分についてはオンプレミスと基本同じ方法で運用可能ですが、OS・ミドルウェアに基本ログインできないPaaSを利用する場合は考慮が必要です。また、VMだとしてもクラウド事業者が管理している部分で障害が発生した場合の検知は、エージェントでは検知できない場合もありますのでこちらも対策が必要となります。
Azureで設定しておいたほうが良い障害監視をご紹介します。
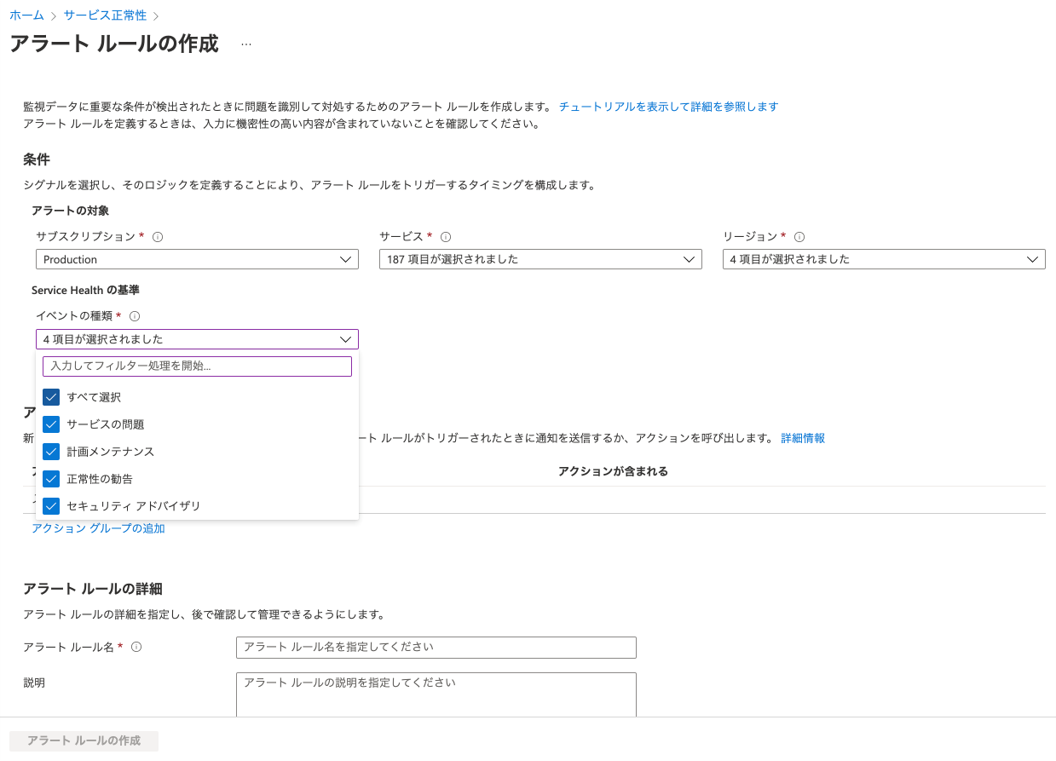
・Azure Service Health
Azure内の計画メンテンナンスや大規模障害が発生した場合に通知を受け取ることができます。利用しているリージョン、サービスを選択し、通知先の設定を行うことで検知することができますので、新しい環境を構築した際は設定しておくことをおすすめします。ただし、実際の障害が発生してから通知されるまでにタイムラグがあるため、これだけで万全というわけではありません。
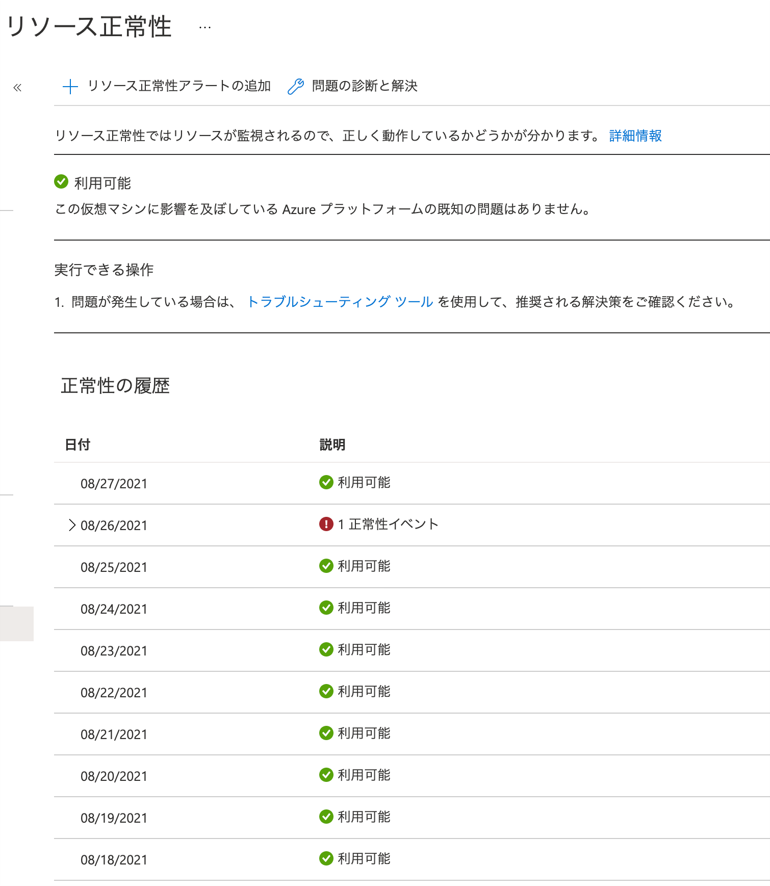
・Azure Resource Health
作成したリソース(VM、等)に影響がある問題を検知・診断することができますのでこちらも必ず設定しておくとよいでしょう。過去に発生した障害も確認することができます。
性能監視・分析
性能監視もPaaSではエージェントが入れられないため、クラウドが提供する監視機能を利用する必要があります。
・Application Insight
アプリケーションパフォーマンスモニタリングを行うことができるAzureの監視機能です。言語はC# 、VB (.NET) 、Java 、Node.JS 、Python に対応しており、アプリケーションマップ、リソース間のレスポンスタイムを可視化が可能です。
閾値を超えた場合のアラート通知はもちろんのこと、定期的なパフォーマンス・チューニングを行う際のデータとしても活用できます。利用者数やデータの増大に伴いシステムの性能は劣化していくことが多いため、このようなデータを元に運用の中で定期的に見直していくことが重要です。
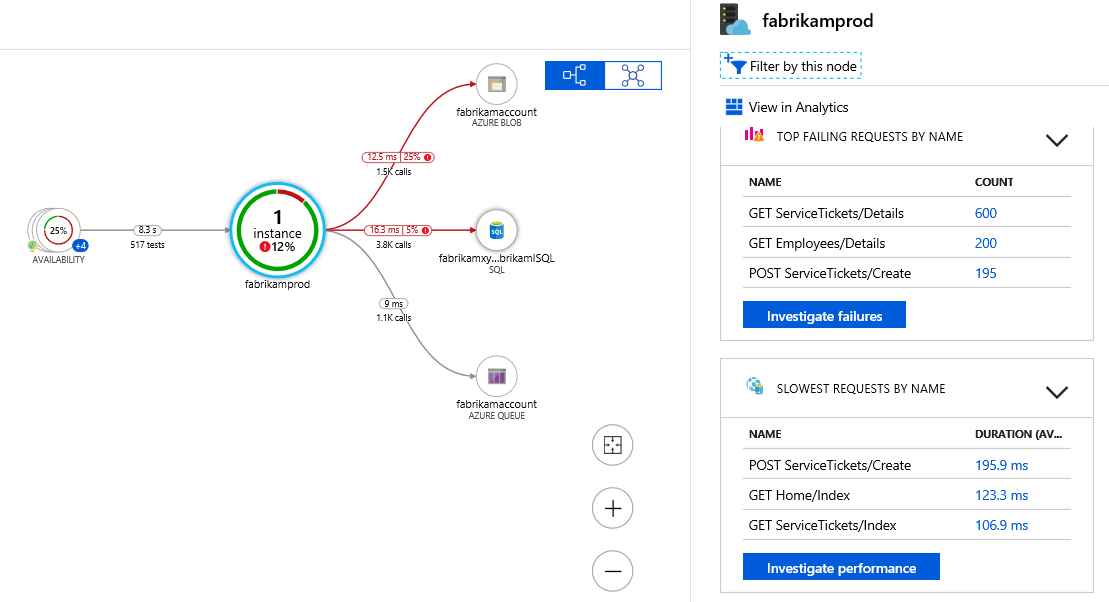
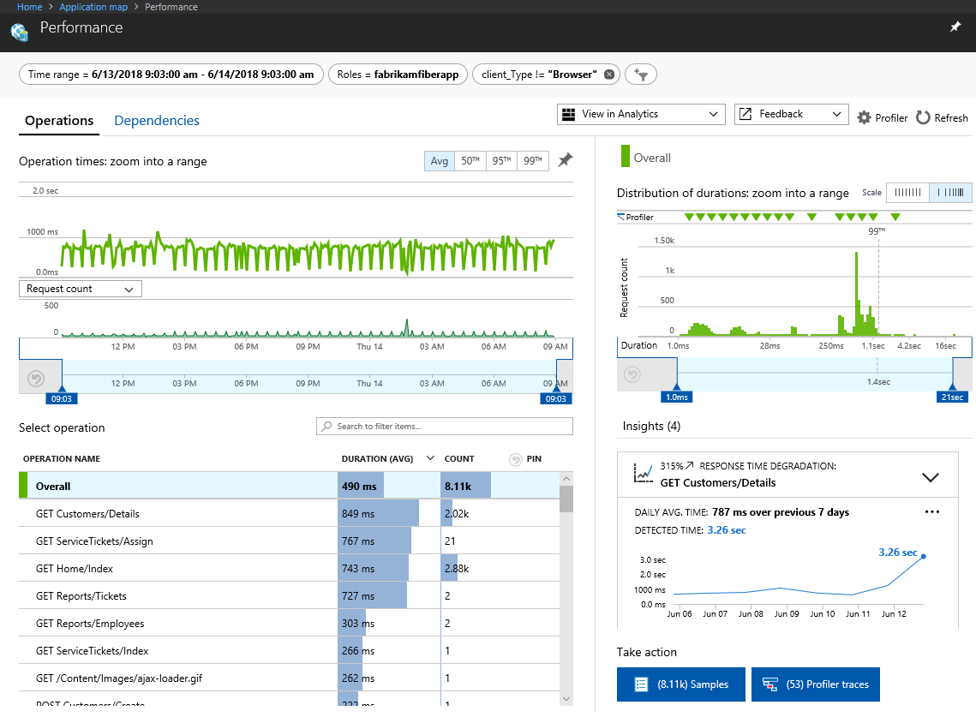
出典:https://docs.microsoft.com/ja-jp/azure/azure-monitor/app/app-map
・Azure SQL Database の Query Performance Insight
利用しているデータベースがAzure SQL Database(SQL ServerのPaaS)を利用している場合、どのクエリが時間がかかっており、システム全体の性能に影響を与えているかをQuery Performance Insightを利用して分析することができます。
(Query Performance Insightで確認できる情報)
・データベース リソース (DTU) の消費量の詳細情報
・CPU、期間、および実行回数別の上位データベース クエリの詳細情報
・クエリの詳細にドリルダウンして、クエリ テキストやリソース使用率の履歴を表示
・データベース アドバイザーからのパフォーマンスに関する推奨事項
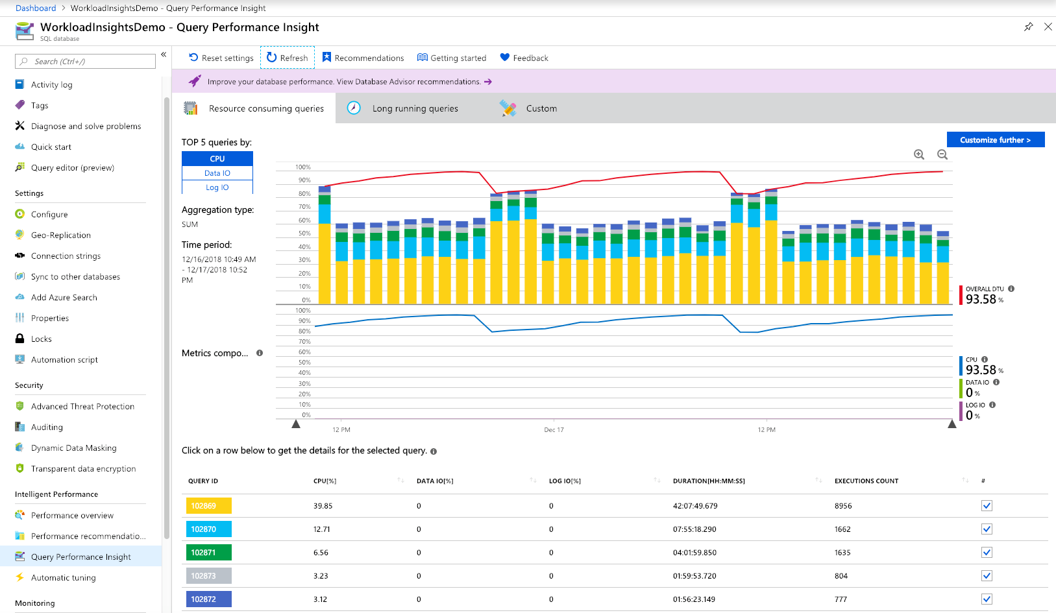
出典:https://docs.microsoft.com/ja-jp/azure/azure-sql/database/query-performance-insight-use
Query Performance InsightはAzure Database for PostgreSQL、MySQLでも利用可能ですので、オープンソース系のアーキテクチャでも活用できます。
バックアップ
クラウドに移行したVMはクラウド標準の機能でバックアップを取得できます。Azure ではAzure Backupを利用することでバックアップサーバやストレージを用意しなくても取得するタイミング、保存期間を設定するだけで安全にシステムバックアップが取得可能です。
ただし、設定した時間にバックアップは始まったものの終了まで異常に時間がかかっていたり、バックアップが失敗することがまれにあります。システムによってはバックアップのタイミングがずれることでリストア時に不具合が発生してしまう、バックアップが失敗していて直近の状態に戻せいないというは困る、、、そのような事象が発生した場合には検知できるようにしておいたほうが良いでしょう。
Azure Backupの機能で失敗時にアラートを通知させることができますので、こちらは設定しておくことをおすすめします。
バックアップにかかった時間でアラートを通知させる機能は無いため、CLIなどで情報を取得し監視する仕組みを必要に応じて入れておくと良いでしょう。
課金管理
クラウドに移行したばかりのシステムが実際にどのくらいの費用が発生しているのかを運用の中で定期的に確認することはとても重要です。VMの費用はおそらく事前に見積もった費用から大きくずれることは少ないですが、トラフィック課金やログをLog Analyticsに保存している場合、思わぬ費用が請求されている場合があります。
トラフィックやログは実際にシステムが利用されないとデータ量の見積もりが難しいため、リリース後は特に監視情報や課金情報から確認しておいたほうが良いでしょう。
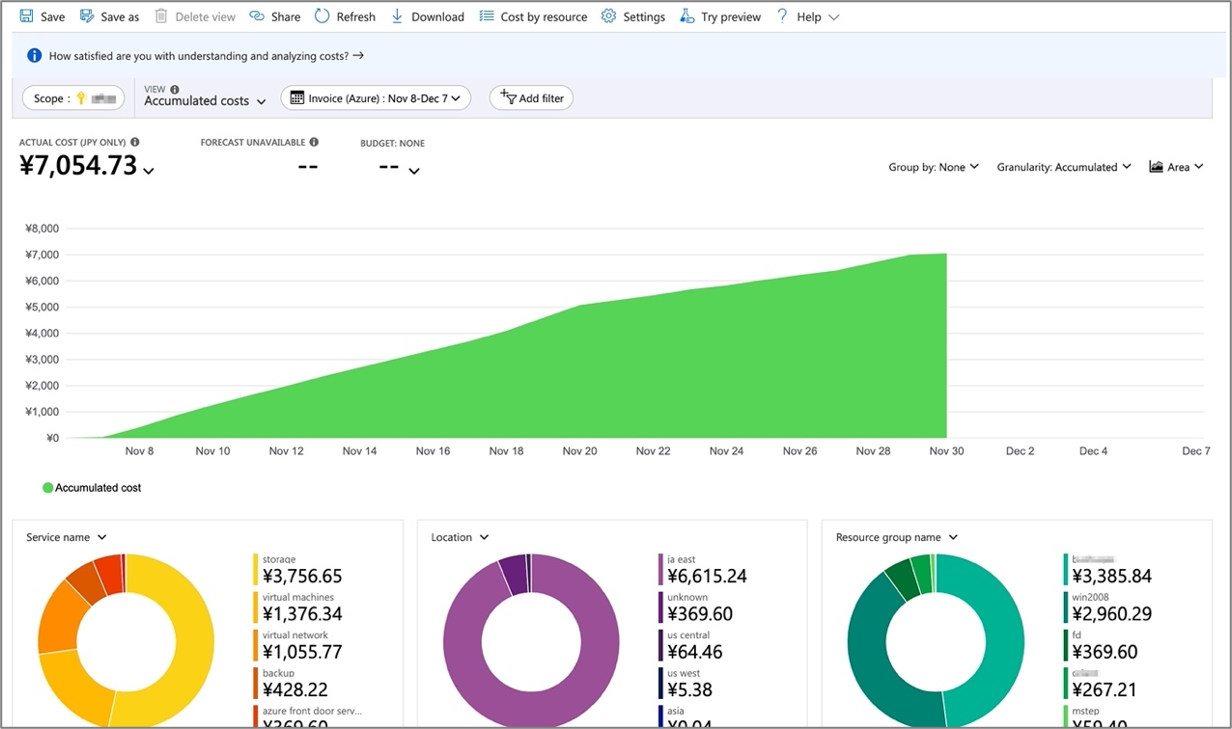
Azureのコスト分析でサービス毎の現在の費用を確認できます。また、予算を設定し、一定以上の費用が発生している場合にはアラートを通知するよう最初に設定しておくことをおすすめします。
自動化
運用の中で自動化は作業を効率化するだけでなく、手順書のコード化、冪等性の実現、オペレーションミスの削減など多くのメリットがあります。慣れないと自動化の工数がかかって面倒に感じるかもしれませんが、なれてくると自動化の作業自体が技術的にも面白くなってきますので是非チャレンジしてください。
AzureにはAutomationやFunctionsなどを利用して、アラートの通知をトリガーにVMを再起動したり、ログ情報を取得して管理者に通知したりすることができます。
Infrastructure as a Code(IaC)
システムに変更がかかった場合、その履歴や最新の構成情報を管理できていることはシステムそのもののサービス品質を高める意味でも非常に重要です。クラウドでは構成情報をコードで管理する仕組みがあり、AzureではARM Template (Azure Resource Template)、またはTerraformを利用することが多いです。
ARM TemplateはMicrosoft純正の機能ですので、最新のサービスにも対応しているのがメリットです。特に制限がない場合はARM Templateを利用するのが良いでしょう。他のクラウドを利用していて、Terraformで管理している場合はAzure環境もTerraformで管理することで少ない学習コストでIaCを実現できます。
ARM TemplateはPortal画面から作成した環境をJSON形式でエクスポートすることができますので、最新の構成情報をコードで管理しておくだけでも有効でしょう。
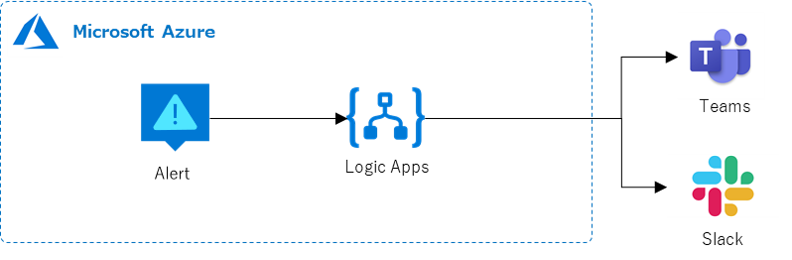
(余談)Chat Ops
アラートの通知はメールではなくSlackやTeamsに通知させる、必要に応じてチャットからコマンドを発行してAzureを操作するChat Opsの活用も多くなってきているかと思います。AzureではLogic Appsを利用することでSlackやTeamsといった主要なコミュニケーションサービスと接続して、簡単にインテグレーションすることが可能ですのでChat Opsを実装する際には利用してみると良いでしょう。
まとめ
今回はオンプレミスでは必要なかったクラウドならではの運用のポイントをご紹介しました。システムのサービスレベルとDesign for Failureに基づいた運用設計を行い、コードによる構成管理と自動化された運用手順を行うことで運用担当者は安心してシステムを運用することができます。
とはいえ最初から完璧に行う必要はなく、クラウドの特性になれながら徐々に最適な形に近づけていくのもよいでしょう。運用の継続的な改善も重要な運用項目の一つだと思いますし、運用自体がクリエイティブな活動となり担当者の技術レベル向上、モチベーションアップにつながることを願っています!
次回は「オンプレミスでは必要なかったセキュリティのポイント」についてご紹介していきます。