

概要
本記事では、Azure Cognitive Servicesで提供されているSpeech serviceのSpeech-to-Textサービスを用いて、リアルタイムな音声認識および音声ファイルのテキスト化をおこなうWebアプリを構築する手順を説明します。WebアプリケーションフレームワークとしてASP.NET Core 5.0を使用します。
目次
-
Speech-to-Textサービスの概要
-
準備
-
リアルタイム音声認識アプリの構築
-
音声ファイルテキスト化アプリの構築
-
まとめ
1. Speech-to-Textサービスの概要
1.1 Speech-to-Textサービスとは?
Speech-to-Textサービスは、Azure Cognitive ServicesのSpeech serviceが提供するサービスの1つで、リアルタイムな音声認識や話者の識別、翻訳などができるサービスです。Speech serviceはSpeech-to-Textの他にも、Text-to-SpeechやVoice assistantsなどのサービスを提供しています。
Speech serviceの概要
https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/overview
対応言語
https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support
価格
https://azure.microsoft.com/ja-jp/pricing/details/cognitive-services/speech-services/
1.2 Speech-to-Textサービスの利用方法
Azureサブスクリプション内でSpeech serviceリソースを作成し、SDKおよびREST APIを通じてサービスを利用します。SDKはC#、C++、Java、Python、JavaScriptなどの言語で利用することができます。
Speech-to-Textのドキュメント
https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/index-speech-to-text
2. 準備
Webアプリ構築の準備として.NETのインストールとSpeech serviceリソースの作成をおこないます。
2.1 .NETのインストール
開発環境に.NETをインストールします。本記事では .NET 5.0を使用します。
https://docs.microsoft.com/ja-jp/dotnet/core/install/
2.2 Speech serviceリソースの作成
(1) Azure Portal(https://portal.azure.com)にアクセスし、[リソースの作成]を選択します。
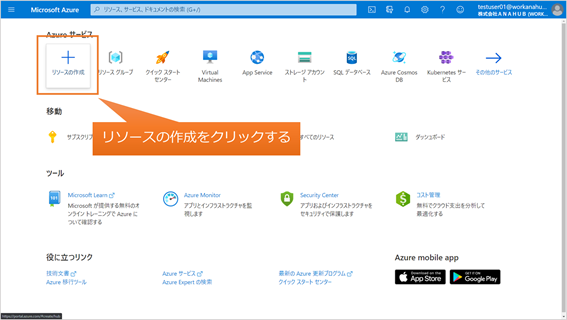
(2) 検索窓に speech と入力してEnterキーを押し、[音声]の[作成]、[音声]の順にクリックします。
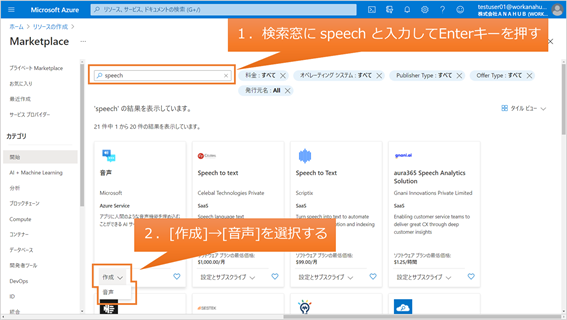
(3) 名前、サブスクリプション、場所、価格レベル、リソースグループの各項目を入力して、[作成]をクリックします。本記事では場所を東日本、価格レベルをFree F0としています。

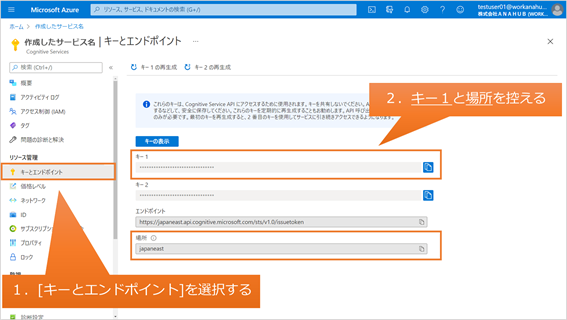
(4) 作成したSpeech serviceに移動し、リソース管理の[キーとエンドポイント]を表示します。後ほどアプリで利用するため、キー1および場所についてメモしておきます。
3. リアルタイム音声認識アプリの構築
Speech SDK for JavaScriptを用いて、リアルタイムな音声認識をおこなうWebアプリを構築します。Speech serviceのキー情報をサーバから取得し、マイクからの入力音声をSpeech serviceを用いてテキスト化します。
※ 本記事ではLinux上で開発をおこなっていますので、Windowsなど別OSで開発される場合は、NuGetパッケージのインストール方法などを適宜読み替えてください。
3.1 Webアプリの作成
(1) 最初にベースとなるWebアプリを作成して起動します。
|
$ dotnet new webapp -o SpeechToText $ cd SpeechToText $ dotnet run |
(2) ブラウザを起動してアプリに接続します。接続先URLは https://localhost:5001 です。
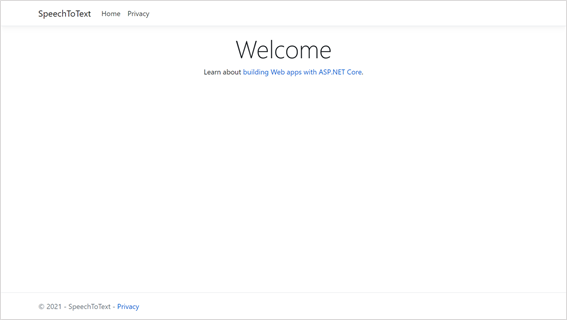
(3) 端末でCtrl+Cを押してアプリを終了します。
3.2 サーバ側の設定
(1) 必要なパッケージを追加します。端末で以下のコマンドを実行します。
|
$ dotnet add package Newtonsoft.Json $ dotnet add package Microsoft.CognitiveServices.Speech |
(2) appsettings.jsonにキー情報を記載します。2.2 (4) でメモしたキー1および場所をそれぞれ記載します。
appsettings.json
|
{ "Logging": { "LogLevel": { "Default": "Information", "Microsoft": "Warning", "Microsoft.Hosting.Lifetime": "Information" } }, "AzureSpeech": { "Key": "Your Key", "Region": "Your Region" }, "AllowedHosts": "*" } |
(3) Speech serviceを扱うためのSpeechクラスを作成します。
|
$ mkdir Services $ touch Services/Speech.cs |
Services/Speech.cs
|
using System.Threading.Tasks; using Microsoft.Extensions.Logging; using Microsoft.Extensions.Configuration; using Microsoft.CognitiveServices.Speech;
namespace SpeechToText.Service { public interface ISpeech { object GetCredential(); }
public class Speech : ISpeech { private readonly ILogger<Speech> _logger; private readonly SpeechConfig _speechConfig;
public Speech(ILogger<Speech> logger, IConfiguration configuration) { _logger = logger;
// appsettings.jsonからSpeechの資格情報を取得 var configs = configuration.GetSection("AzureSpeech"); _speechConfig = SpeechConfig.FromSubscription(configs["Key"], configs["Region"]); }
public object GetCredential() { return new { Key = _speechConfig.SubscriptionKey, Region = _speechConfig.Region }; } } } |
(4) Startup.csのConfigureServicesにおいて依存性の注入をおこないます。
Startup.cs
|
~省略~ using Microsoft.Extensions.DependencyInjection; using Microsoft.Extensions.Hosting; using SpeechToText.Service;
namespace SpeechToText { ~省略~ public void ConfigureServices(IServiceCollection services) { services.AddRazorPages(); services.AddScoped<ISpeech, Speech>(); } ~省略~ |
(5) Index.cshtml.csを修正します。
Pages/Index.cshtml.cs
|
using System; using System.Collections.Generic; using System.Linq; using System.Threading.Tasks; using Microsoft.AspNetCore.Mvc; using Microsoft.AspNetCore.Mvc.RazorPages; using Microsoft.Extensions.Logging; using SpeechToText.Service;
namespace SpeechToText.Pages { public class IndexModel : PageModel { private readonly ILogger<IndexModel> _logger; private readonly ISpeech _speech; public string CredStr;
public IndexModel(ILogger<IndexModel> logger, ISpeech speech) { _logger = logger; _speech = speech;
var cred = _speech.GetCredential(); CredStr = Newtonsoft.Json.JsonConvert.SerializeObject(cred); }
public void OnGet() {
} } } |
3.3 クライアント側の設定
(1) Speech SDK for JavaScriptをダウンロード(https://aka.ms/csspeech/jsbrowserpackage)してwwwroot/lib/speech/ ディレクトリに展開します。
|
$ cd ~/Downloads $ unzip SpeechSDK-JavaScript-1.17.0.zip $ cd – $ cp -r ~/Downloads/SpeechSDK-JavaScript-1.17.0 wwwroot/lib/speech |
(2) JavaScriptファイルを作成します。
|
$ touch wwwroot/js/speech.js |
wwwroot/js/speech.js
|
'use strict';
let recognizer = null; let timerId = null; let outText = ''; let language = 'ja-JP';
function recognizeMicStart() { // recognizerの初期化 const speechConfig = SpeechSDK.SpeechConfig.fromSubscription(cred.Key, cred.Region); speechConfig.speechRecognitionLanguage = language; const audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput(); recognizer = new SpeechSDK.SpeechRecognizer(speechConfig, audioConfig);
// イベントハンドラの登録 (recognizing, recognized, canceled) recognizer.recognizing = (s, e) => { if (e.result.reason === SpeechSDK.ResultReason.RecognizingSpeech) { let text = e.result.text; $('#outtext').val(outText + text); } }
recognizer.recognized = (s, e) => { if (e.result.reason === SpeechSDK.ResultReason.RecognizedSpeech) { let text = e.result.text + '\n'; outText += text; $('#outtext').val(outText); } }
recognizer.canceled = (s, e) => { $('#notice').text('音声認識がキャンセルされました'); }
// 音声認識の開始 outText = ''; $('#outtext').val(outText); $('#micbtn').text('Stop'); $('#notice').text('音声認識しています。なにか話してください'); recognizer.startContinuousRecognitionAsync();
// タイムアウト処理の登録 timerId = setTimeout(() => { recognizer.stopContinuousRecognitionAsync(); $('#micbtn').text('Start'); $('#notice').text('タイムアウトしました'); }, 30000); }
function recognizeMicStop() { // 音声認識の停止 clearTimeout(timerId); recognizer.stopContinuousRecognitionAsync(); $('#micbtn').text('Start'); $('#notice').text(''); }
// ボタンクリック時の処理 $('#micbtn').click(function () { if ($(this).text() == 'Start') { recognizeMicStart(); } else { recognizeMicStop(); } }); |
(3) Index.cshtmlを以下のように変更します。
Pages/Index.cshtml
|
@page @model IndexModel @{ ViewData["Title"] = "Speech to text"; }
<div class="row"> <div class="col-1"></div> <div class="col-3"> <div> <label>マイク入力</label> <button type="button" id="micbtn" class="btn btn-primary btn-block">Start</button> </div> </div> <div class="col-7"> <p>音声認識結果 <span id="notice" class="text-danger"></span></p> <textarea id="outtext" style="height: 300px; width: 100%"></textarea> </div> <div class="col-1"></div> </div>
@section Scripts{ <script type="text/javascript"> let cred = @Html.Raw(Model.CredStr); </script> <script src="~/lib/speech/microsoft.cognitiveservices.speech.sdk.bundle.js"></script> <script src="~/js/speech.js"></script> } |
3.4 Webアプリを起動してテストします。
(1) アプリを起動してブラウザから接続します。接続先URLは https://localhost:5001 です。
|
$ dotnet run |
(2) Startボタンを押して音声認識を開始します。入力した音声がリアルタイムにテキスト化されます。Stopボタンを押すか、30秒経つと自動的に終了します。
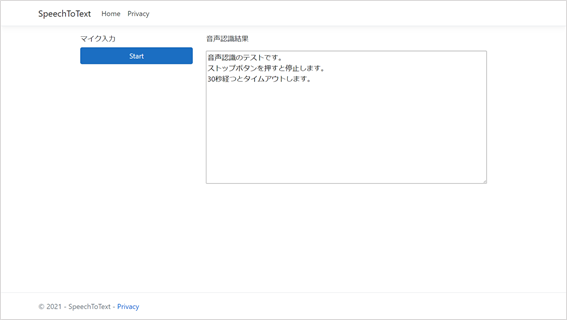
※ ブラウザの設定でマイクの使用を許可する必要があります。

(3) 端末でCtrl+Cを押してアプリを終了します。
3.5 解説
(1) サーバ側の設定では、Speechクラスを定義してcsにおいて依存性の注入をおこなこうことで、IndexModelからSpeechインスタンスにアクセスできるようにしています。IndexModelではSpeech serviceのキー情報を取得して文字列化し、ブラウザ側から参照できるようにCredStrにキー情報を格納しています。
依存性の注入について
https://docs.microsoft.com/ja-jp/aspnet/core/fundamentals/dependency-injection?view=aspnetcore-5.0
(2) クライアント側の設定では、CredStrキー情報を取得して、recognizerの初期化をおこないrecstartContinuousRecognitionAsync()メソッドで音声認識を開始しています。recognizer.stopContinuousRecognitionAsync()が実行されるまで音声認識が継続しますが、recognizerは発話の区切りを検知する都度recognizedイベントを発生させてその発話の認識結果を送ってきます。発話の途中でもrecognizingイベントが発生しますが、このイベントで得られるテキストはrecognizedイベント時に更新されます。もし1つの発話だけを認識すればよいのであればrecognizer.recognizeOnceAsync()メソッドを用いることもできます。
Speech SDK for JavaScript
Speech SDK for JavaScriptのセットアップ
4. 音声ファイルテキスト化アプリの構築
Speech SDK for C#を用いて、音声ファイル(WAV)をテキスト化するWebアプリを構築します。ブラウザからWAVファイルをアップロードしてSpeech serviceを用いてテキスト化します。
※ 本記事ではLinux上で開発をおこなっていますので、Windowsなど別OSで開発される場合は、NuGetパッケージのインストール方法などを適宜読み替えてください。
4.13リアルタイム音声認識アプリの構築 で作成したアプリをベースに進めます。
4.2 サーバ側の設定
(1) Speechクラスを更新します。
Services/Speech.cs
|
using System.Threading.Tasks; using Microsoft.Extensions.Logging; using Microsoft.Extensions.Configuration; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.AspNetCore.Http; using System.IO;
namespace SpeechToText.Service { public interface ISpeech { object GetCredential(); Task<string> GetTextFromFile(IFormFile formFile); }
public class Speech : ISpeech { private readonly ILogger<Speech> _logger; private readonly SpeechConfig _speechConfig;
public Speech(ILogger<Speech> logger, IConfiguration configuration) { _logger = logger;
// appsettings.jsonからSpeechの資格情報を取得 var configs = configuration.GetSection("AzureSpeech"); _speechConfig = SpeechConfig.FromSubscription(configs["Key"], configs["Region"]); }
public object GetCredential() { return new { Key = _speechConfig.SubscriptionKey, Region = _speechConfig.Region }; }
public async Task<string> GetTextFromFile(IFormFile formFile) { // アップロードされたファイルをローカルに保存 var filePath = Path.GetRandomFileName(); filePath = Path.Combine("wwwroot", filePath); using (var stream = File.Create(filePath)) { await formFile.CopyToAsync(stream); }
// recognizerの初期化 _speechConfig.SpeechRecognitionLanguage = "ja-JP"; using var audioConfig = AudioConfig.FromWavFileInput(filePath); using var recognizer = new SpeechRecognizer(_speechConfig, audioConfig);
// イベントハンドラの登録 (Recognized, Canceled) var stopRecognition = new TaskCompletionSource<int>(); string outText = null;
recognizer.Recognized += (s, e) => { if (e.Result.Reason == ResultReason.RecognizedSpeech) { outText += e.Result.Text + "\n"; } };
recognizer.Canceled += (s, e) => { _logger.LogInformation($"CANCELED : {e.Reason}"); stopRecognition.TrySetResult(0); };
// 音声認識の開始 await recognizer.StartContinuousRecognitionAsync();
// キャンセルイベントの発生を待つ Task.WaitAny(new[] { stopRecognition.Task });
// 後処理(ファイル削除) File.Delete(filePath);
return outText; } } } |
(2) Index.cshtml.csを更新します。
Pages/Index.cshtml.cs
|
using System; using System.Collections.Generic; using System.Linq; using System.Threading.Tasks; using Microsoft.AspNetCore.Mvc; using Microsoft.AspNetCore.Mvc.RazorPages; using Microsoft.Extensions.Logging; using SpeechToText.Service; using System.IO; using System.ComponentModel.DataAnnotations; using Microsoft.AspNetCore.Http;
namespace SpeechToText.Pages { public class IndexModel : PageModel { private readonly ILogger<IndexModel> _logger; private readonly ISpeech _speech; public string CredStr; [BindProperty(SupportsGet = true)] public string Notice { get; set; } [BindProperty(SupportsGet = true)] public string OutText { get; set; } [BindProperty] public SingleFileUpload FileUpload { get; set; }
public IndexModel(ILogger<IndexModel> logger, ISpeech speech) { _logger = logger; _speech = speech;
var cred = _speech.GetCredential(); CredStr = Newtonsoft.Json.JsonConvert.SerializeObject(cred); }
public void OnGet() {
}
public async Task<IActionResult> OnPostUploadAsync() { if (!ModelState.IsValid) return Page();
Notice = $"{FileUpload.FormFile.FileName} を読み込みました"; OutText = await _speech.GetTextFromFile(FileUpload.FormFile);
return RedirectToPage("./Index", new { Notice, OutText }); }
public class SingleFileUpload { [Required] [Display(Name = "WAVファイル")] public IFormFile FormFile { get; set; } } } } |
4.3 クライアント側の設定
(1) Index.cshtmlを更新します。
Pages/Index.cshtml
|
@page @model IndexModel @{ ViewData["Title"] = "Speech to text"; }
<div class="row"> <div class="col-1"></div> <div class="col-3"> <div> <label>マイク入力</label> <button type="button" id="micbtn" class="btn btn-primary btn-block">Start</button> </div> <p></p> <form enctype="multipart/form-data" method="post"> <label>ファイル入力</label> <input asp-for="FileUpload.FormFile" type="file"> <span asp-validation-for="FileUpload.FormFile"></span> <button type="submit" asp-page-handler="upload" class="btn btn-primary btn-block mt-1">Upload</button> </form> </div> <div class="col-7"> <p>音声認識結果 <span id="notice" class="text-danger">@Model.Notice</span></p> <textarea id="outtext" style="height: 300px; width: 100%">@Model.OutText</textarea> </div> <div class="col-1"></div> </div>
@section Scripts{ @{await Html.RenderPartialAsync("_ValidationScriptsPartial");} <script type="text/javascript"> let cred = @Html.Raw(Model.CredStr); </script> <script src="~/lib/speech/microsoft.cognitiveservices.speech.sdk.bundle.js"></script> <script src="~/js/speech.js"></script> } |
4.4 Webアプリを起動してテストします。
(1) アプリを起動してブラウザから接続します。接続先URLは https://localhost:5001 です。
|
$ dotnet run |
(2) ファイル選択ボタンを押して音声ファイルを選んだ後、Uploadボタンを押すとテキスト化されます。対応しているのはWAVファイルのみです。
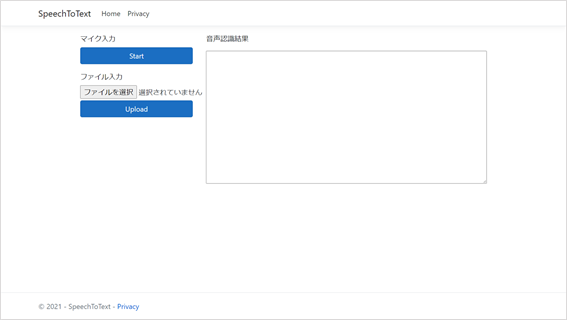
(3) 端末でCtrl+Cを押してアプリを終了します。
4.5 解説
(1) サーバ側の設定では、Speechクラスを拡張してWAV音声ファイルをテキスト化するメソッドを実装しています。音声ファイルを最後まで処理するとCanceledイベントが発生するので、このイベントをトリガーにして後処理をおこなっています。
Speech SDK for C#
(2) クライアント側の設定ではファイルのサーバへのアップロードを実装しています。また、音声認識結果を表示するためIndexModelのNoticeおよびOutTextを参照しています。ファイルアップロードについては、音声ファイルのサイズが大きい場合はストリーミングを用いた実装をおこなう必要があります。
ASP.NET Coreのファイルアップロードについて
https://docs.microsoft.com/ja-jp/aspnet/core/mvc/models/file-uploads?view=aspnetcore-5.0
5. まとめ
本記事では、Speech serviceのSpeech-to-Textサービスを用いて、リアルタイムな音声認識および音声ファイルのテキスト化をおこなうASP.NET Core Webアプリを構築する手順を説明しました。Speech-to-Textサービスには他にもBlob Storageに保存された大容量の音声データをテキスト化する機能や話者を識別する機能などもあり、会議の文字起こしやアプリケーションのUI/UXの改善など様々な用途に活用できるのではないでしょうか。
~~連載記事一覧~~